
Introduction
인공 신경망이란 무엇인가?
시냅스의 결합으로 네트워크를 형성한 인공 뉴런이 학습을 통해서 서로 간의 결합의 세기를 조정해 문제 해결능력을 갇는 비선형 모델

종류
- 지도 학습
- 비지도 학습
- 강화 학습
구조
- 입력
- 말 그대로 입력되는 방대한 양의 데이터를 의미
크게 자연어와 이미지로 분류됨
- 모델(뉴런)
가중치 값으로 구성된 행렬으로 입력값을 가중치 값에 곱해 hypothesis 값을 산출해 낸다
- 활성화 함수
뉴런을 통해 들어온 값을 특정한 함수를 통해 활성화 시키고 비 활성화시킨다
- loss function
여러 뉴런을 통해 산출된 결과 값은 loss function을 통해 실제 정답과의 간격을 산출 해낸다. 그 간격을 최소화 하는 과정이 학습이다.
- Optimization fuction
- 가상의 출력값과 결과값 사이의 가상의 loss function이 있을 때 최소한의 loss로 도달하기 위해 사용할 수학적 방법

뉴런 구조
활성화 함수
- Sigmoid

A sigmoid function is a mathematical function having a characteristic “S”-shaped curve or sigmoid curve.
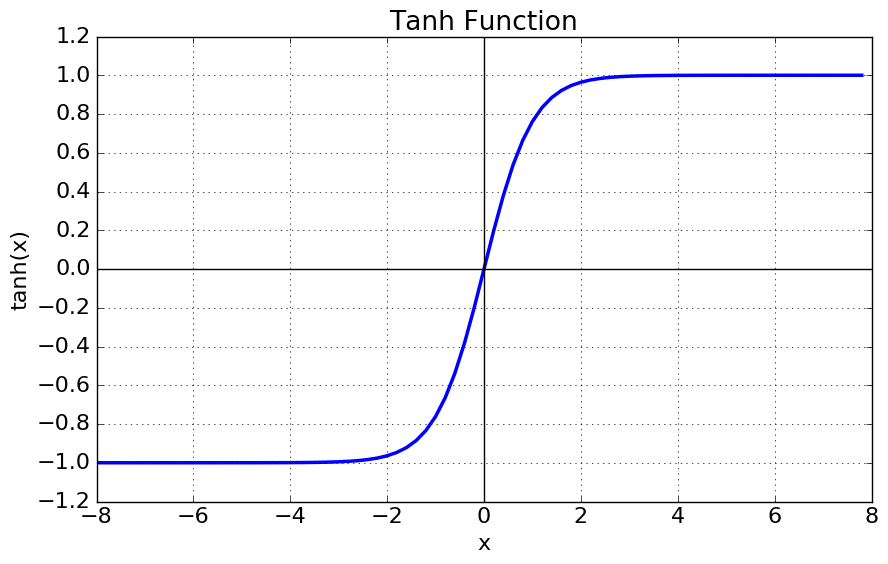
- 층이 깊어질수록 기울기 소실이라는 단점을 가지고 있어 잘 사용하지 않는 것 같다.
- 웨이트의 업데이트 방향이 전부 positive기 때문에 zigzag로 업데이트 되는 현상이 발생하고 이는 학습을 느리게 만드는 주범이 된다.
- Relu
the rectifier is an activation function defined as the positive part of its argument
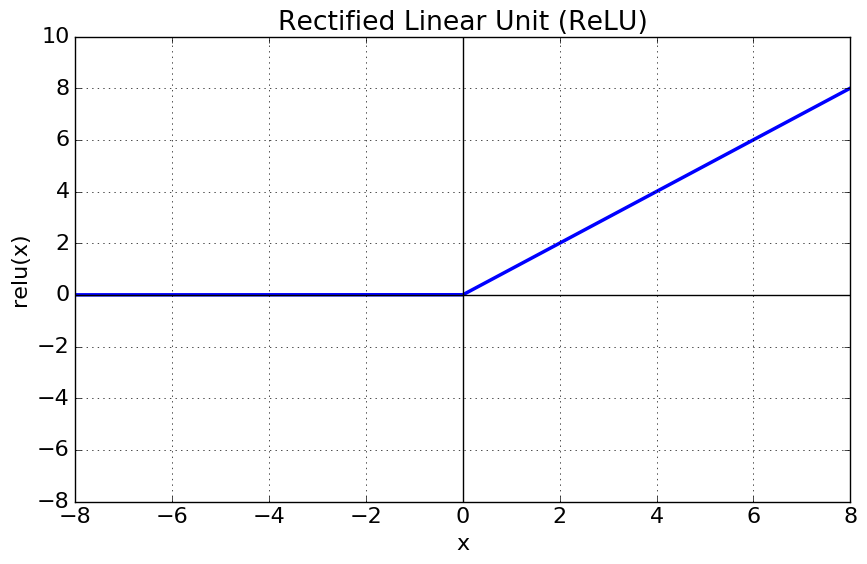
- 학습 속도가 빠르고 구현이 간단하다
- x<0 일때는 뉴런이 죽을 수 있는 단점이 존재한다.
loss function
- Cross Entropy
이른바 원-핫 코딩을 할 때 유효한 수단이 되며, Y가 범주형 데이터일 때 Y^가 추정한 각각의 확률을 이용해 계산한다.
- Soft-max
어진 벡터의 값들을 [0,1]에 바운드 시키고 확률분포의 조건을 만족시키게 하는 함수다.
Optimization Function(Optimizer)
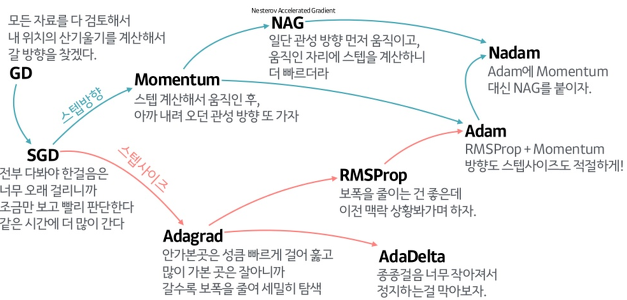
- GD, SGD(경사하강, 확률적 경사하강)
- 경사하강의 경우 최적해를 찾기 전에 학습이 멈출수도 있고
- 확률적 경사하강법은 단일 반복에서 기울기를 구할 때 사용되는 데이터가 1개여서 노이즈가 너무 심하다는 한계가 있습니다. 그래서 mini batch를 사용함으로 이를 보완 할 수 있습니다.
- adagrad
학습을 통해 크게 변동이 있었던 가중치에 대해서는 학습률을 감소시키고 학습을 통해 아직 가중치의 변동이 별로 없었던 가중치는 학습률을 증가시켜서 학습이 되게끔 한다.

- AdaGrad는 무한히 학습하면 어느 순간 h가 너무 커져서 학습이 아예 안될 수 있다. 이를 RMSProp에서 개선
- Momentum
SGD에 momentum개념을 추가한 것이다. 현재 batch로만 학습하는 것이 아니라 이전의 batch 학습결과도 반영한다.
- Adam
Momentum과 RMSProp를 융합한 방법이다.